Demos
Demos




















































![]()
Healthcare Language Has Very Specific Needs


Our Healthcare NLP Experience
We trained domain-specific deep learning models to extract from free-text reports tumor size, staging, laterality, localization, and grading.
Non-urgent findings in radiology reports are not always pursued – with harmful consequences. We trained detailed fact extraction models from free-text reports to enable consistent follow-up.
Clinical depression is under-diagnosed but can often be picked up from signals in patients’ free-text clinical notes. We used information extraction techniques on unified patient records to enable acting on predicted or suspected depression in advance.
Predicting how many hospital beds and nurses of each certification will be needed is important to providing quality service and avoiding gridlock. Using features from free-text emergency room notes significantly improved accuracy over time series models that only used structured data.
Prior authorization is now required by many US payers for dozens of procedure codes. Automated question answering from pre-auth request forms reduces costs and enables patients to get the treatment they need faster.
Less than 10% of safety events are formally reported – but mining progress notes can uncover medication changes other consequences of such events. Entity and fact extraction models enable a much better estimation & classification of safety events.
Accurately predicting how many adverse events are expected to occur due to a drug – as well as the type of events and their severity – is becoming increasingly more feasible. This combines traditional machine learning and deep learning techniques with NLP pipelines that mine better information from reports and academic papers.
This project builds a continuously updating knowledge graph that maps the relationships between researchers, diseases, therapies and genes. It required the combination of domain-specific NLP models and embeddings trained on PubMed, current ontologies and terminologies, and a clinical team for labeling and measurement.
Participating in a clinical trial requires a patient to match a long list of eligibility criteria. This cannot be done using structured data from EHR systems and hence requires either lengthy manual processes – or advanced domain-specific NLP models.
Clinical coders must often read through 100+ pages of documentation for a single patient – resulting in mistakes and missed revenue. Applying OCR, summarization, clinical entity resolution and case complexity classification enables more cases to be done faster and accurately.
Assigning Evaluation & Management clinical codes requires understanding of fuzzy concepts such as the complexity of clinical decision making and the physical exam. Automated this coding task from free-text visit summaries requires accurate NLP & ML models which are accurate, consistent and explainable.
When fraud is suspected based on analyzing medical claims, the next step is to read the encounter notes. This is a slow and expensive manual process – unless it can be automated by applying question answering, semantic similarity and entity resolution models at scale.
State Of The Art Accuracy
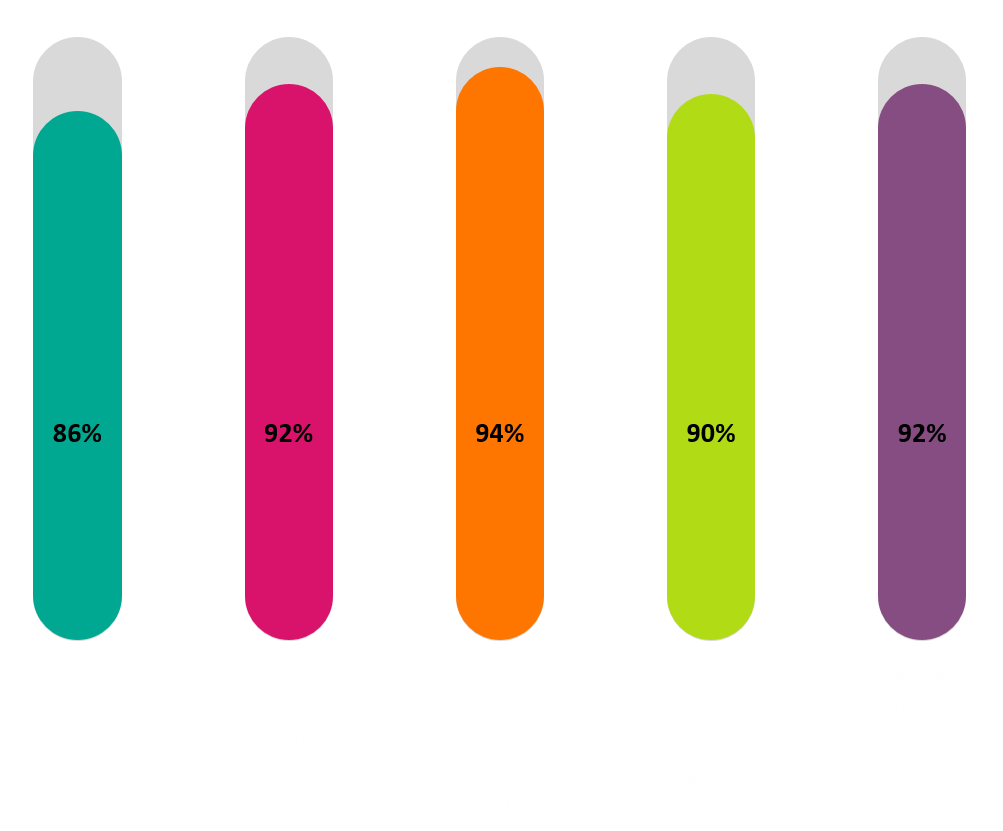
F-Score Results
Productization of the following research Papers
-
“ Entity Recognition from Clinical Texts via Recurrent Neural Network”, Liu et al., BMC Medical Informatics & Decision Making, July 2017.
-
“CNN-based ranking for biomedical entity normalization”, Li et al., BMC Bioinformatics, October 2017.
-
“Neural Networks For Negation Scope Detection“, Fancellu et al., In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016.
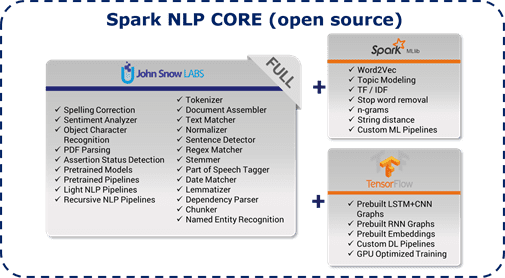
What’s In the Box