





 Demos
Demos




















































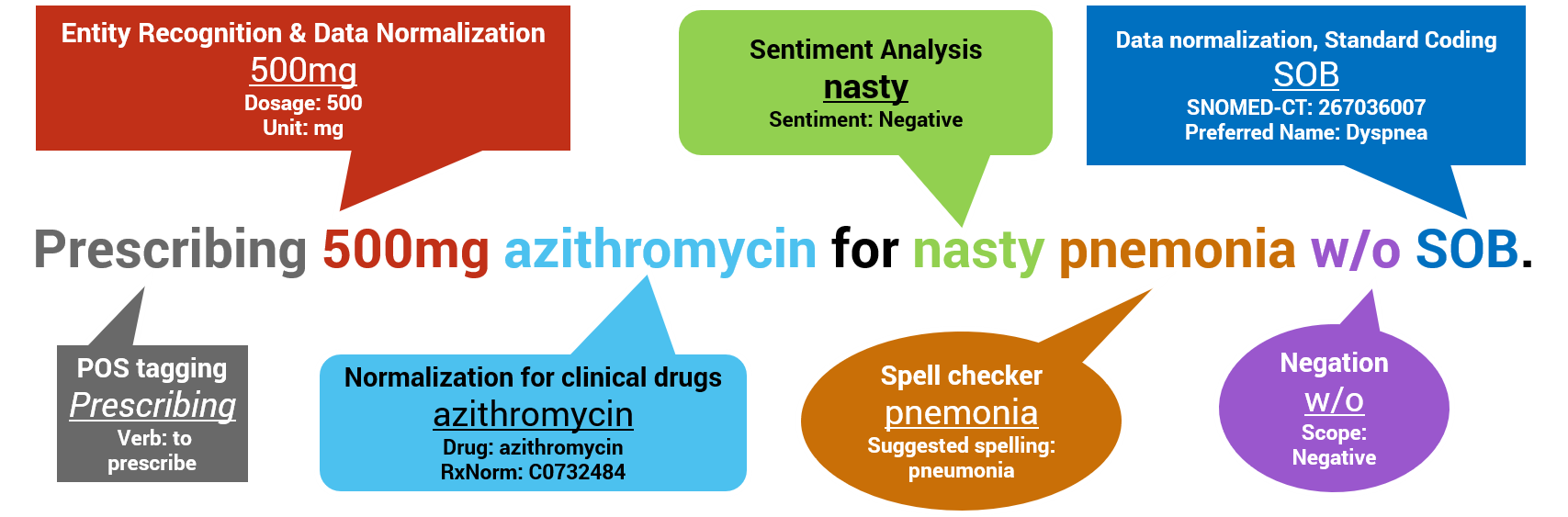
What’s in the Box

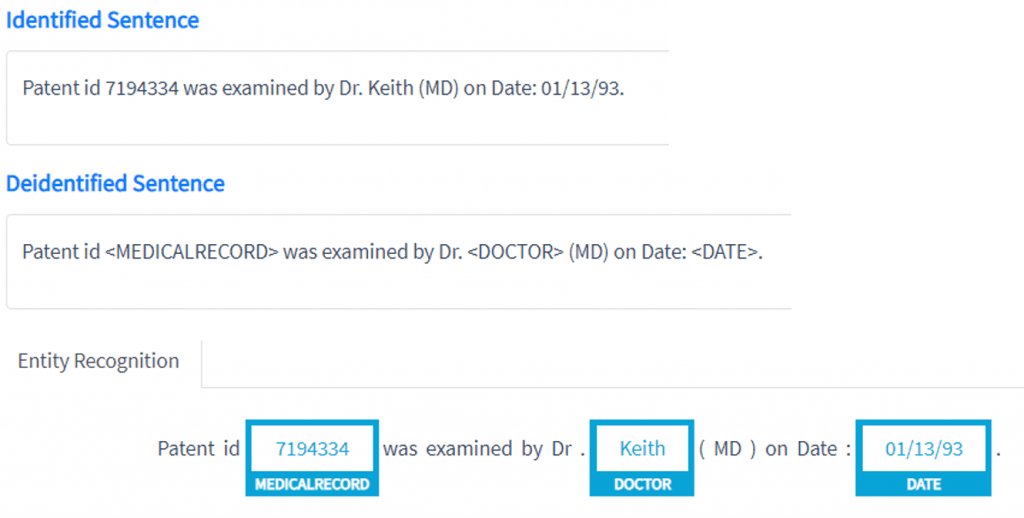
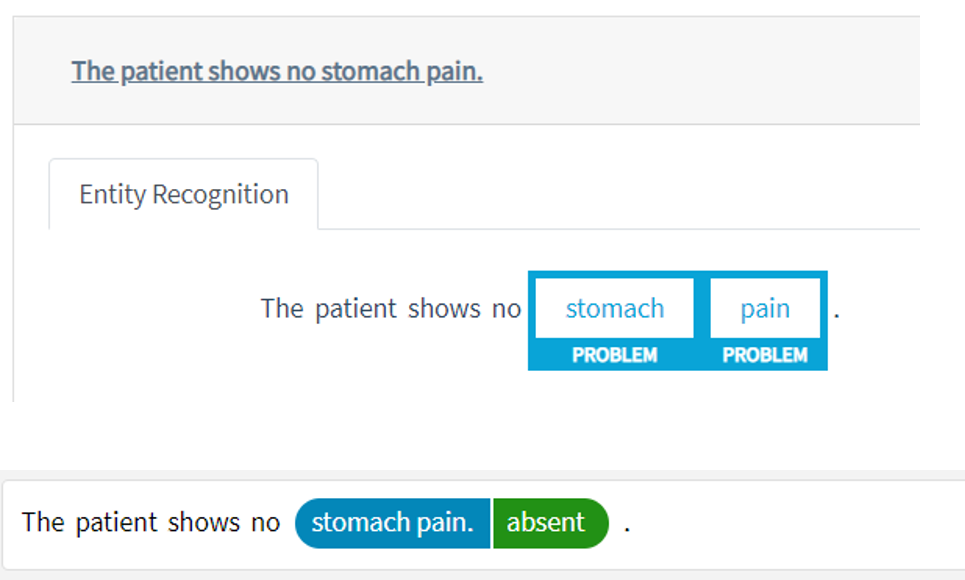

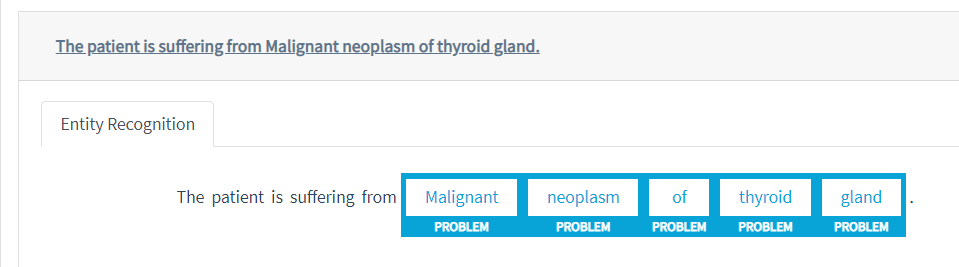
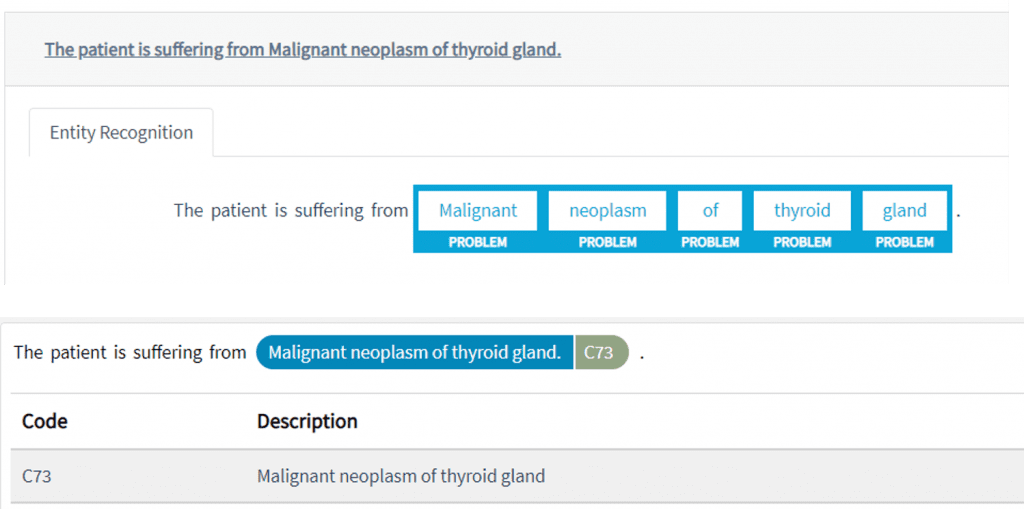
State Of The Art Accuracy
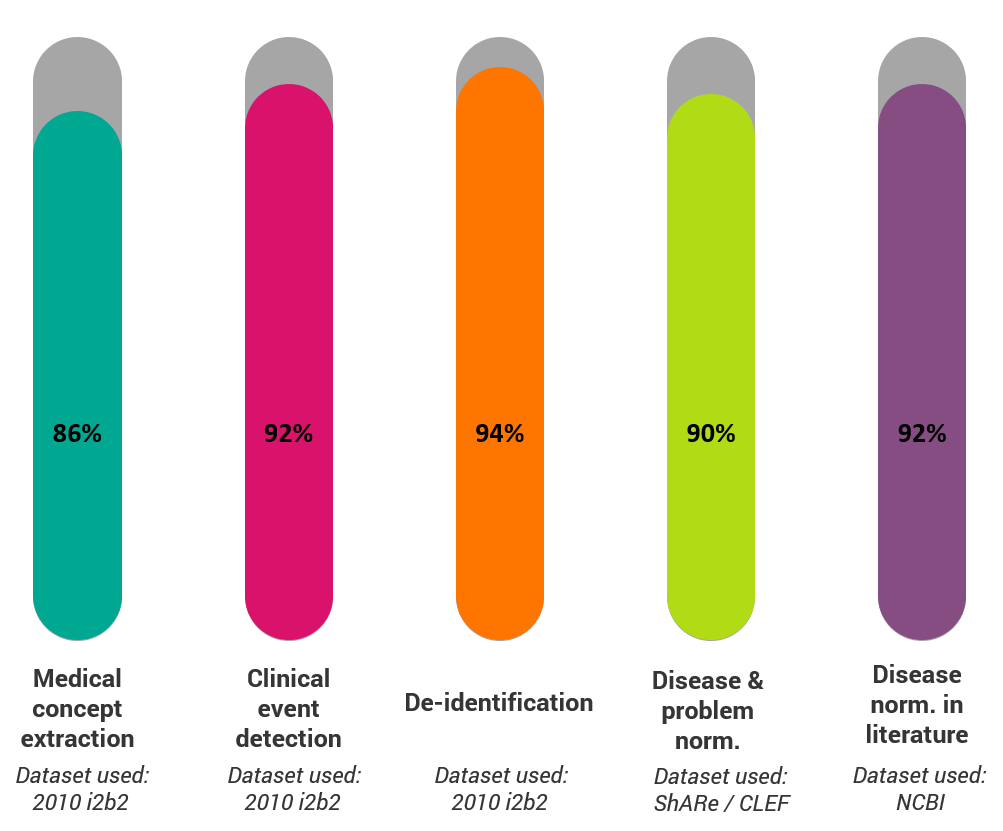
F-Score Results
Production-Grade, Fast & Trainable Implementation of State-of-the-Art Biomedical NLP Research
-
“BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, CoRR, 2018
-
“Entity Recognition from Clinical Texts via Recurrent Neural Network”, Liu et al., BMC Medical Informatics & Decision Making, July 2017.
-
“CNN-based ranking for biomedical entity normalization”, Li et al., BMC Bioinformatics, October 2017.
-
“Neural Networks For Negation Scope Detection“, Fancellu et al., In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016.
-
“How to Train Good Word Embeddings for Biomedical NLP, Billy Chiu, Gamal Crichton“, Anna Korhonen, Sampo Pyysalo, Proceedings of the 15th Workshop on Biomedical Natural Language Processing, 2016
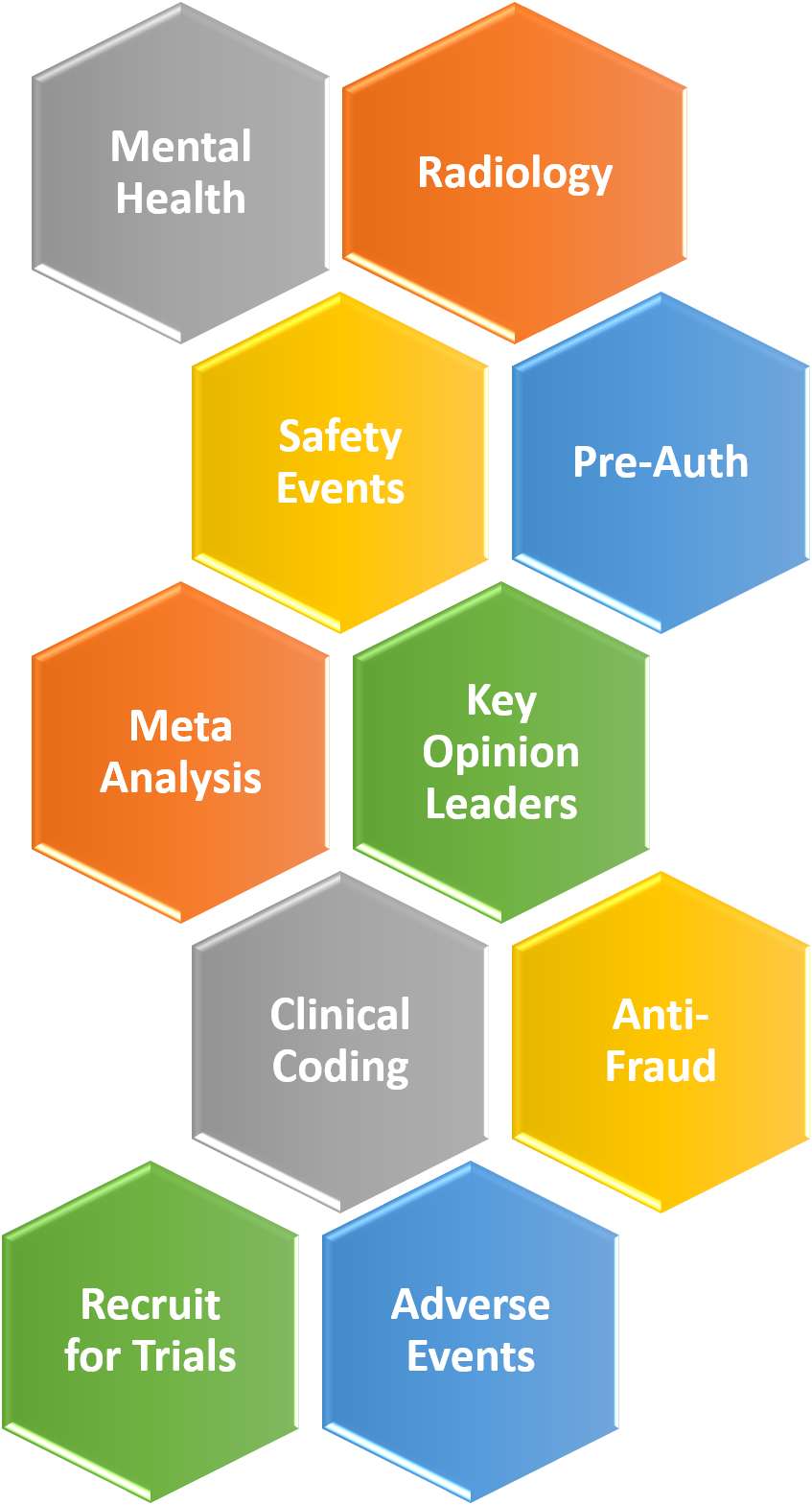
Proven success across healthcare
[popup_anything id=”38186″]
