





 Demos
Demos





















































By all accounts, John Snow Labs has created the most accurate software in history to extract facts from unstructured text.

Why Spark OCR?

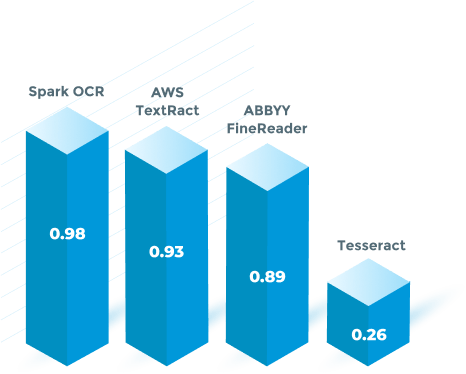
Unmatched Accuracy
Apply deep learning techniques that combine Computer Vision and Text Mining to accurately extract facts from documents & images based on hints from text, layout, and formatting.

OCR Software F1 Score

Extract more than text
Combine computer vision, OCR, and NLP models to classify documents, extract normalized entities and figures, find signatures on forms, extract data from tables, and de-identify images.


Works on Real-World Images
Tune & train your own models to improve image quality and optimize accuracy. Used in production on old faxes, low-quality scans, noisy forms, crumpled receipts, blurry photos, and everything in between.


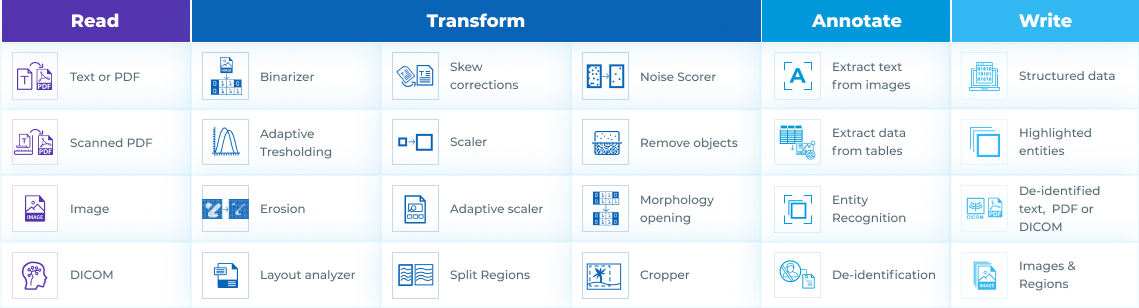
Read, Edit, Write
Go beyond reading text to recognize named entities, correct spelling, de-identify data – and generate new PDF or DICOM documents that highlight these results
What’s in the box
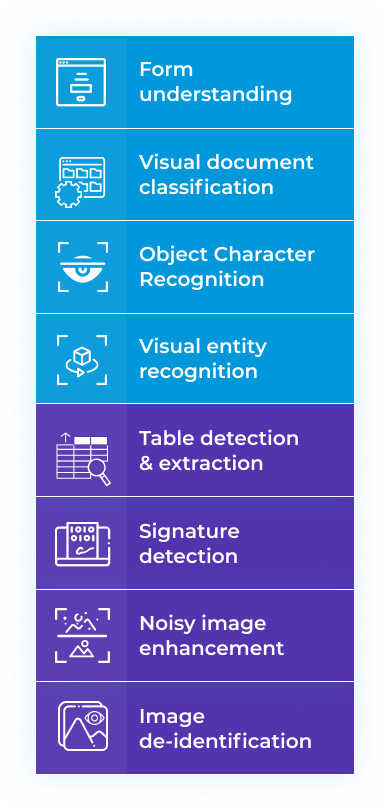





Trainable & Tunable

Scalable to a Cluster

Fast Inference

Hardware Optimized

Community
Spark OCR in Action

Extract data from
images & forms
images & forms
Extract and normalize specific facts & figures from custom images and forms, by training your own models to learn where in the image, next to which words, and using what formatting the facts you’re interested in are.
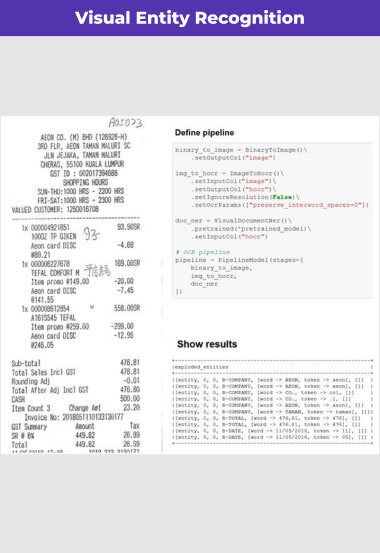


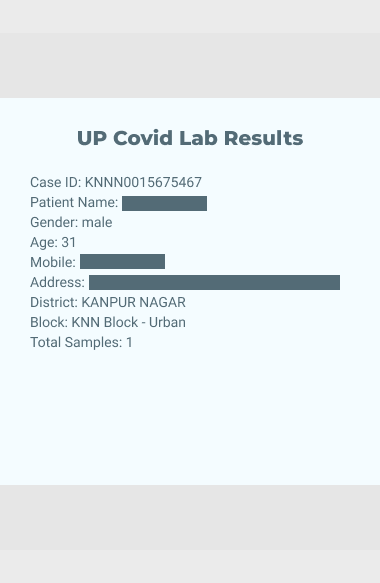
Extract whole tables
Find tables in images, visually identify rows and columns, and extract data from cells into data frames. Turn scans from financial disclosures, academic papers, lab results and more into usable data.

Recognize entities
in scanned PDFs
in scanned PDFs
End-to-end example of regular NER pipeline: import scanned images from cloud storage, preprocess them for improving their quality, recognize text using Spark OCR, correct the spelling mistakes for improving OCR results and finally run NER for extracting entities.



Correct skewness in
scanned documents
scanned documents
Correct the skewness of your scanned documents will highly improve the results of the OCR. Spark OCR is the only library that allows you to finetune the image preprocessing for excellent OCR results.

Recognize text in natural scenes
By using image segmentation and preprocessing techniques Spark OCR recognizes and extracts text from natural scenes.



Remove background noise from scanned documents
Removing the background noise in a scanned document will highly improve the results of the OCR. Spark OCR is the only library that allows you to finetune the image preprocessing for excellent OCR results.

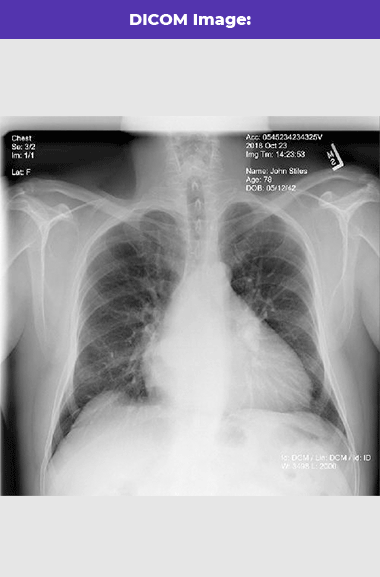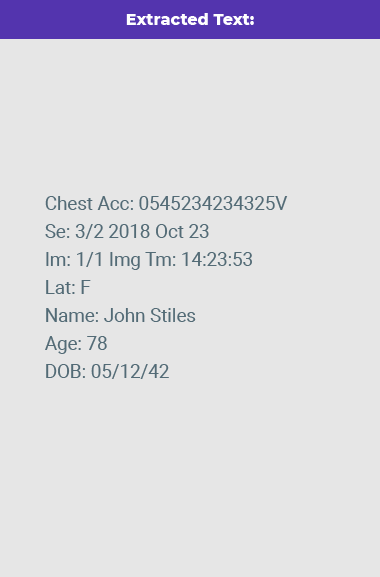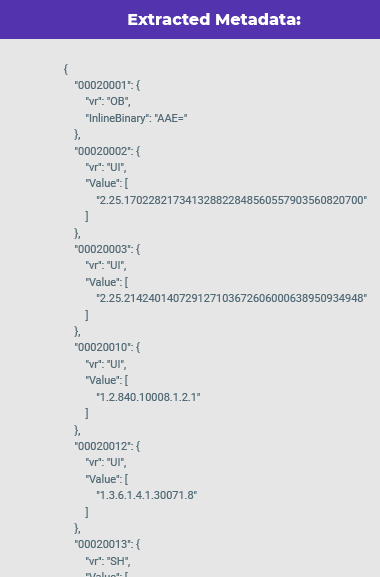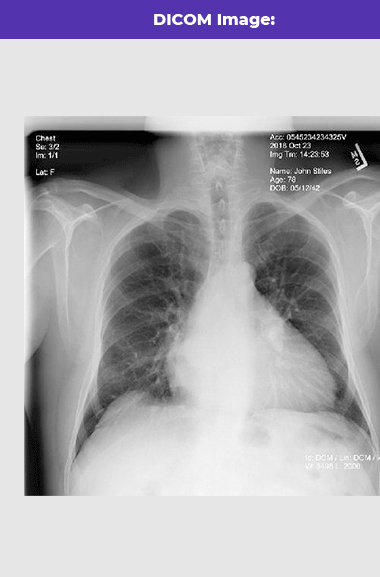
DICOM to Text
Recognize text from DICOM format documents. This feature explores both the text on the image and the text from the metadata file.
